パート1: さあ、はじめましょう¶
はじめに¶
すこし前のことですが、 Twisted の メーリングリスト に「Twisted の入門用の文書は死の淵にあるね」という趣旨の 投稿 がありました。まったくもってそんなことはありません。Twisted と Python での非同期プログラミングの入門用の文書に関しては、真逆にあるかもしれません。もし時間がなかったり我慢強くなければ、これはあなたが探している入門用の文書ではありません。
あなたが非同期プログラミングの初学者ならば、手っ取り早い入門用の文書に巡り合うことはまぁ無理だろうとも信じています。少なくともあなたは天才でないでしょうし。私は何年も Twisted を使ってきて、どうやって自分が最初に (ゆっくりと) 学び、何が難しいのかを考えてくるうちに、数をこなすことが大事なのではなく、非同期コードを書いて理解するために要求される「メンタルモデル」の獲得が大事であるとの結論に達しました。Twisted のソースコードのほとんどは明快でしっかり書かれており、オンラインで読めるドキュメントも良質です。たいていのフリーソフトウェアを基準にした場合に、です。しかし、メンタルモデルがなければTwisted のコードベースや Twisted を使っているコードを読むことや、大量のドキュメントを読むことでさえ、困惑したり頭を悩ますことにしかならないでしょう。
このため、この入門の最初のパートでは読者がモデルを理解しやすいように配慮し、Twisted の機能紹介は後回しにしています。実際、はじめは Twisted をまったく使わず、その代わりに、どのようにして非同期システムが動作するかを説明するための簡単な Python プログラムを使います。そして Twisted を使うようになると、日々のプログラミングでは通常は使わないであろう低レベルな部分から始めるでしょう。Twisted は高度に抽象化されたシステムで、問題を解くときに飛躍をもたらせてくれます。しかし、Twisted を学んでいるときや、Twisted が実際にどうやって動作しているか理解しようとしているときでさえ、多くの抽象化されたレベルはトラブルを引き起こします。ですから、基本的なことから始めて内から外へ話を進めていきましょう。
ひとたびメンタルモデルを獲得すると、 Twisted のドキュメント を読んだり ソースコードを眺める ことははるかに簡単に感じられると思います。それでは始めましょう。
モデル¶
同期モデルとの違いを明確にするために、(願わくば) お馴染みのふたつのモデルから始めることにしましょう。図にしてみると、プログラムを完了するため動作してなくてはならない、概念的に独立な三つのタスクからなるプログラムを想像できますね。これらのタスクは、後で具体的にしますが、今のところはプログラムがそれらを動作させなければならないこと以外は何も言及しません。私が「タスク」という言葉を「実行される必要がある何か」という非技術的な意味で使っていることに注意してください。
最初のモデルはお馴染みのシングルスレッドの同期モデルです。下の図1を見てください。
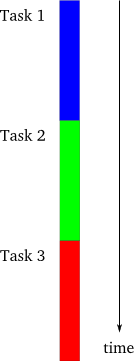
図1:同期モデル¶
これはプログラミングでもっとも単純な形式です。それぞれのタスクは一度のひとつずつしか実行されず、他のタスクが開始される前にあるタスクは完全に終了します。タスクが常に決まった順番で実行されるならば、後で実行されるタスクの実装では、事前に実行される全てのタスクはエラーがなく終了しておりそれらの出力を利用可能である、と仮定できます。論理的に非常に単純化されます。
同期モデルと対照的なものとして、図2に示すスレッドモデルが挙げられます。

図2:スレッドモデル¶
このモデルでは、それぞれのタスクは別々のスレッド制御の元で実行されます。スレッドはオペレーティングシステムによって管理され、複数のプロセッサやコアを持つシステムでは真に並列に実行され、単一プロセッサのシステムでは細切れにして一緒くたに実行されます。スレッドモデルで大事な点は、実行の詳細 は OS によって制御されますので、プログラマーは同時に実行されるかもしれない一連の独立した命令という観点で考えればよい、ということです。ダイアグラムは単純ですが、スレッドがお互いに協調する必要がありますので、実際のスレッドプログラミングは非常に複雑になりえます。スレッド間通信とスレッドの協調は一歩進んだプログラミングのトピックであり、正しく使うのは難しいものです。
複数のスレッドの代わりに複数のプロセスを使って平行性を実装しているプログラムもあります。プログラミングの詳細は異なりますが、私たちの目的からすれば図2で示したものと同じモデルです。
いよいよ図3で非同期のモデルを紹介します。
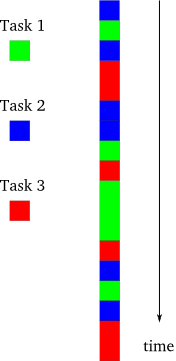
図3:非同期モデル¶
このモデルでは、タスクは細切れにされますが、単一のスレッドで制御されます。プログラマはあるタスクが実行されており他のタスクは実行されていないことを常に知っていますので、スレッドの場合よりは単純です。単一プロセッサのシステムではスレッドプログラムも同様に動作しますが、複数プロセッサのシステムに移植したときにプログラムが不正に動作しないように、スレッドを使うプログラマは図3ではなく図2の観点で考えるべきです。しかし、シングルスレッドの非同期システムは常に細切れにされて実行されるでしょう。たとえ複数プロセッサのシステム上であったとしても。
非同期とスレッドのモデルにはもうひとつの違いがあります。スレッドシステムでは、あるスレッドを一時停止させて他のスレッドを実行するという決定はプログラマーが制御する範疇にはありません。むしろオペレーティングシステムの仕事であり、プログラマはほとんど全ての場合においてスレッドは一時停止して他のスレッドに置き換えられると考えなくてはいけません。これに対して、非同期モデルでは明示的に他のタスクに制御を譲るまでタスクは実行し続けるでしょう。これはスレッドの場合からの更なる単純化です。
同じシステムで非同期とスレッドのふたつのモデルを混ぜたり一緒に使うこともできることに注意してください。しかし、この文書のほとんどでは単一スレッド制御での実直な非同期システムを扱います。
動機¶
ここまでで、スレッドモデルより非同期モデルの方が単純であることをみてきました。単一の命令処理の流れしかなく、タスクが任意の時点で停止させられるのではなく、明示的に制御を譲るからです。しかし、非同期モデルは同期のものに比べて明らかに複雑です。プログラマーはそれぞれのタスクを断続的に実行されるさらに小さなステップの流れとして構成しなくてはなりません。そして、もしあるタスクが他のタスクの出力を使っていれば、その依存したタスクは、全てをまとめたものではなく一連の断片や部分として入力を受け入れるように記述しておかなければなりません。実際の平行性はありませんので、非同期プログラムは同期のものと同じくらい長々と実行されるでしょう。もしかすると、非同期プログラムが貧弱な 参照の局所性 を露呈するかのように、より長い実行時間になるかもしれません。
それでは、なぜ非同期モデルを使うことを選択するのでしょう?これには少なくとも二つの理由があります。ひとつ目は、ひとつ以上のタスクが人間とのやり取りを受け持っていれば、タスクを細切れに分割することによって、システムは他のタスクを「バックグラウンド」で動作させながらユーザーからの入力を待ち続けられます。システムはバックグラウンドのタスクを高速に実行しないかもしれませんが、人間が使う分には喜ばしいことでしょう。
しかしながら非同期システムが同期のものより単純にうまく動作するには、時として劇的に、全てのタスクを全体として短時間で実行するという意味ですが、条件があります。この条件は図4に表すように、タスクが強制的に待たされたりブロックされるときに発生します。
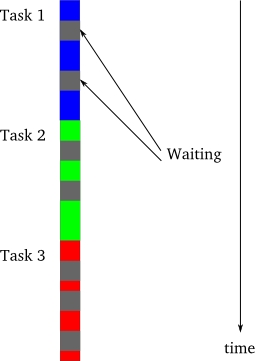
図4:同期プログラミングでのブロッキング¶
この図では、灰色の部分が特定のタスクが待っていて (ブロックしていて) 進捗がない期間を表しています。なぜタスクがブロックされるのでしょうか?もっとも典型的な理由は入出力 (I/O) 操作や外部機器に対するデータ転送を待つことです。典型的な CPU は、ディスクやネットワーク経由で利用可能なものに対して比較にならないほど高速にデータを転送できます。つまり、たくさんの入出力を伴う同期プログラムは、ディスクやネットワークが追いつくまで多くの時間をブロックされることになるでしょう。このような同期プログラムはその理由からブロッキングプログラムとも呼ばれます。
図4(ブロッキングプログラム)はちょっとだけ図3(非同期プログラム)のようにも見えることに注意してください。偶然の一致ではありません。非同期モデルの背後にある基本的な考え方は、同期プログラムにおいて普通はブロックするであろうタスクに直面したときに、進められる他のタスクを代わりに実行する、ということです。非同期プログラムは進められるタスクが何もないときにブロックするだけなので、ノンブロッキングプログラムと呼ばれます。また、あるタスクから他のタスクへのスイッチは、一番最初のタスクが終了するかブロックしなければならない状況に達したかのどちらかに対応しています。潜在的に大量のブロッキングタスクがあると、大雑把にいって個別のタスクに費やす実時間は同じくらいですが全体としての待ち時間が短くなるため、非同期プログラムは同期のものに比べて大幅に性能を向上させられます。
同期モデルと比較して非同期モデルが性能を発揮するのは次の場合です。
大量のタスクがあり、ほとんど常に少なくともひとつは進められるタスクがあるとき。
タスクが大量の入出力をさばき、他のタスクが実行できるかもしれないのに、同期プログラムがブロックして大量に時間を無駄にさせてしまうとき。
タスクがお互いに独立で、タスク間の通信がほとんど必要ないとき。(それゆえ、あるタスクが他のタスクを待つ必要がない)
これらの条件は、クライアント・サーバーの環境において、ほとんど完全に典型的な高負荷のネットワークサーバー (Web サーバーなど) のことを表しています。それぞれのタスクとは、リクエストを受け取ってそれに返答を送るような入出力を伴うクライアントからのリクエストを意味します。そして、クライアントのリクエスト (ほとんどが読み込み) はたいがいは独立しています。このため、ネットワークサーバーの実装は非同期モデルにとって最も当てはまりやすく、それゆえに Twisted は何と言ってもネットワークのためのライブラリなのです。
次は¶
これでパート1は終わりです。”パート2: ゆったりした詩と世紀末”ではいくつかのネットワークプログラムを書きます。ブロッキングとノンブロッキングの両方で、できる限り簡単に (Twisted を使わずに) 非同期の Python プログラムが実際に動作する雰囲気をつかんでもらうためです。