パート21: おろそかにならないようにゆっくりと: Twisted と Haskell¶
はじめに¶
前回は Twisted と Erlang が共通に持っているいくつかの考えに細心の注意を払いながら、それぞれを比べました。 非同期 I/O と reactive プログラミングが Erlang ランライムとプロセスモデルの鍵となるコンポーネントですから、結局のところ、これは非常にシンプルです。
今日はさらに本題を離れて Haskell に目を向けてみましょう。 Erlang とは随分異なる (もちろん Python とも) もうひとつの関数型言語です。 平行して存在するものは多くありませんが、非同期 I/O が隠蔽しているいくつかを覗いていくことになります。
大文字 F の付いた関数¶
Erlang も関数型言語ですが、信頼性の高い並行モデル - reliable concurrency model - に主眼が置かれています。 一方で Haskell はどこまで行っても関数で、 functors と monads のように圏論 (category theory) から持ち込んだ概念を平然と使えるようにします。
でも気にしないでください。こうした概念に深入りするつもりはありません (たとえ可能だとしても)。 その代わり、Haskell のもっと伝統的な関数の機能のひとつ “laziness” に注目していきます。 多くの関数型言語のように (しかし Erlang は違います)、Haskell は遅延評価 (lazy evaluation) をサポートします。 評価が遅延される言語では、プログラムのソースコードは「何を計算するのか」に比べて「どうやって計算するのか」を多くは記述しません。 一般的には、実際に計算を処理することの詳細はコンパイラとランタイムシステムの仕事になります。
この点についてもう少し言及しておくと、遅延評価される計算が進みにつれて、ランタイムはすべてを一斉に実行するのではなく、部分的に (あるいは遅延させて) 文を評価するかもしれません。 一般的に、ランタイムは現在の計算を進めるために必要とされる式だけを評価するでしょう。
次の一行が [1,2,3] というリスト (Haskell と Python はいくつかのリスト構文が一緒です) に head 、リストの最初の要素を取り出す関数、を適用する簡単な Haskell 文です。
head [1,2,3]
GHC Haskell ランタイムをインストールすると、こんな感じで試すことができます。
[~] ghci
GHCi, version 6.12.1: http://www.haskell.org/ghc/ : ? for help
Loading package ghc-prim ... linking ... done.
Loading package integer-gmp ... linking ... done.
Loading package base ... linking ... done.
Prelude> head [1,2,3]
1
Prelude>
結果は予想したように数字の 1 です。
Haskell のリスト構文には、いくつかの先頭要素からリストを定義する使いやすい機能があります。
例えば [2,4 ..] というリストは 2 から始まる偶数の数列になります。
どこで終わるのかって?うーん、終わりません。
Haskell の [2,4 ..] などのリストは (概念的に) 無限リストを表現します。
対話的な Haskell プロンプトでこれを評価してみると分かります。
あなたが入力した式の結果を表示しようとしてくれるでしょう。
Prelude> [2,4 ..]
[2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78,80,82,84,86,88,90,92,94,96,98,100,102,104,106,108,110,112,114,116,118,120,122,124,126,128,130,132,134,136,138,140,142,144,146,
...
実際には終了しませんので、この計算を停止させるためには Ctrl-C を押さなければならないでしょう。
しかし遅延評価のおかげで、Haskell ではこのような無限リストを何の問題もなく使用できます。
Prelude> head [2,4 ..]
2
Prelude> head (tail [2,4 ..])
4
Prelude> head (tail (tail [2,4 ..]))
6
無限リストの最初と二番目と三番目の要素にそれぞれアクセスしていますが、無限ループはどこにも見当たりませんね。
これが遅延評価のエッセンスです。
最初にリスト全体を評価して (こうすると無限ループになってしまいます) リストを head 関数に与えるのではなく、Haskell ランタイムは head がその処理を終えるのに十分な大きさのリストしか構築しません。
リストの残りの部分は決して構築されません。計算を続けるために必要ないからです。
tail 関数を使ってみると、Haskell はリストをさらに構築させられます。しかしここでも、計算の次のステップを評価するために必要な分だけです。
一度計算が終了すると、リストの後ろの部分は捨て去ることができます。
みっつの異なる無限リストを部分的に消費する Haskell コードがあります。
Prelude> let x = [1..]
Prelude> let y = [2,4 ..]
Prelude> let z = [3,6 ..]
Prelude> head (tail (tail (zip3 x y z)))
(3,6,9)
ここでは、すべてのリストを一緒くたにまとめて、tail の tail の head を取得します。 繰り返しになりますが、Haskell は問題なくこれを扱えますし、コードを評価し終えるために必要にしか各リストを構築しません。 図46に Haskell ランタイムが無限リストを消費する - consuming - 様子を図示します。
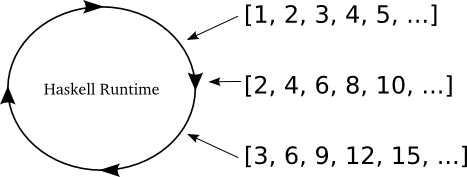
図46:無限リストを消費する Haskell¶
Haskell ランタイムを単純なループとして表現しましたが、複数のスレッドで実装されているかもしれません (Haskell の GHC バージョンを使っているならきっとそうです)。 しかし注意すべき主要なポイントは、この図がいかに、ネットワークソケットからデータを受信するにつれてその部分部分を消費する reactor ループのように見えるかです。
非同期 I/O と reactor パターンを、遅延評価の非常に限定的な形式だと考えることもできます。 非同期 I/O のモットーは「あなたが持っているデータと同じくらいのプロセスのみ持ちます」 1 です。 そして遅延評価のモットーは「あなたが必要とするデータと同じくらいのプロセスのみ必要とします」 2 です。 さらに、遅延評価される言語はこのモットーをほとんどどこにでも適応します。I/O という限られたスコープだけではありません。
しかし遅延評価される言語では、非同期 I/O を使えるようにすることは大きな課題ではないことがポイントです。 コンパイラとランタイムは、データ構造を少しずつ処理するために設計されており、I/O ストリームの入力チャンクを遅延して処理することは当然のことです。 このため Erlang ランタイムのように、Haskell ランタイムはソケット抽象化の一部として非同期 I/O を簡単に取り込めます。 Haskell で詩のクライアントを実装してこのことを見ていきましょう。
Haskell での詩¶
初めての Haskell による詩のクライアントは haskell-client-1/get-poetry.hs にあります。 Erlang のときと同様に、一気に完成バージョンを扱い、もっと学びたくなったときのために、さらに読むべきものを紹介します。
Haskell も軽量スレッドとプロセスをサポートします。Haskell にとっては Erlang のように中心的な役割ではありませんが。 Haskell クライアントはダウンロードしたい詩のそれぞれに対してプロセスを生成します。 ここでキーとなる関数は、軽量スレッド内でソケットに接続し getPoetry 関数を開始する、 runTask です。
このコードの中にたくさんの型宣言があることに気付いたでしょうか。
Haskellは Python や Erlang とは違って静的型付けです。
Haskell は明示的に宣言されていない型を自動的に推論します (推論できない場合はエラーを報告します) ので、個別の変数に型を宣言しません。
Haskell は副作用のあるコード (つまり、I/O を実行するコード) を純粋な関数からきれいに分離することを要求してきますから、たくさんの関数が IO 型 (専門的にはモナドと言います) を含みます。
getPoetry 関数には次の行があります。
poem <- hGetContents h
これは、ハンドル (つまり TCP ソケット) から詩の全体を読み込むために一度だけ出現します。
しかし、普通は Haskell は遅延 - lazy - させます。
Haskell ランタイムは、 select ループ内で非同期 I/O を処理する、ひとつ以上の実際のスレッドを持ちます。
このため、I/O ストリームの遅延評価の可能性を保存しておきます。
この非同期 I/O が本当に続いていくことを見せるために、詩のそれぞれの行におけるタスク情報を出力する “callback” 関数 - gotLine - を含めておきました。 しかし実のところコールバック関数ではありませんし、これを含めるか否かに関わらずプログラムは非同期 I/O を使うでしょう。 この呼び出しでさえ、 “gotLine” は、Haskell プログラムでは問題外である命令法の言語 - imperative-language - の考え方を反映します。 何はともあれ後でもう少し整理するとして、初めての Haskell クライアントを動かしましょうか。 まずはゆっくりした詩のサーバ (slow poetry servers) をいくつか起動します。
python blocking-server/slowpoetry.py --port 10001 poetry/fascination.txt
python blocking-server/slowpoetry.py --port 10002 poetry/science.txt
python blocking-server/slowpoetry.py --port 10003 poetry/ecstasy.txt --num-bytes 30
それでは Haskell クライアントをコンパイルしましょう。
cd haskell-client-1/
ghc --make get-poetry.hs
get-poetry という名前のバイナリファイルが生成されますので、
ようやくサーバに対してクライアントを実行できます。
./get-poetry 10001 10002 1000
次のような出力になります。
Task 3: got 12 bytes of poetry from localhost:10003
Task 3: got 1 bytes of poetry from localhost:10003
Task 3: got 30 bytes of poetry from localhost:10003
Task 2: got 20 bytes of poetry from localhost:10002
Task 3: got 44 bytes of poetry from localhost:10003
Task 2: got 1 bytes of poetry from localhost:10002
Task 3: got 29 bytes of poetry from localhost:10003
Task 1: got 36 bytes of poetry from localhost:10001
Task 1: got 1 bytes of poetry from localhost:10001
...
データの任意の大きさの塊ではなく、詩の各行に対して一行ずつ出力していますので、以前の非同期クライアントとは出力がちょっと違いますね。 しかしお分かりのように、クライアントはひとつずつ順番にではなく、全てのサーバからのデータを一緒に処理しています。 クライアントは他の詩を待つことなく、最初の詩を受信するとすぐに出力することにも気付いたでしょうか。 他の詩の受信はそれぞれのペースで進みます。
よし、クライアントから命令法の残り部分をキレイにして、タスク番号を気にせず、単に詩を受け取るだけのバージョンにしましょう。 haskell-client-2/get-poetry.hs がそれです。 非常に短くなっており、それぞれのサーバに対して、ソケットに接続してデータを受け取って送り返すだけですね。
新しいクライアントをコンパイルしましょう。
cd haskell-client-2/
ghc --make get-poetry.hs
詩のサーバの同じ集合に対して実行します。
./get-poetry 10001 10002 10003
それぞれの詩のテキストが画面に時折表示されるでしょう。
サーバの出力から、それぞれのサーバが同時にデータをクライアントに送っていることが分かるでしょう。 それに加えて、クライアントはできるだけ早く最初の詩の各行を出力します。 他の二つの詩に対して動作している最中でも、詩の残りの部分を待つことはありません。 一つ目が終わると二つ目の詩を素早く出力します。これはずっと蓄積されてきたものです。
私たちが取り立てて何か命令しなくても、これらのすべてが起こります。 コールバックも、あちこちに受け渡されるメッセージもありません。プログラムにやって欲しいことの正確な詳細があるだけです。 実行するためにどうすべきかはこれっぽっちもありませんよね。 残りは Haskell コンパイラとランタイムが面倒をみてくれます。やったね。
議論、さらに読むべきもの¶
Twisted から Erlang、そして Haskell へと移ってくる中で、見える部分から見えない部分まで、非同期プログラミングの背後にある考え方でこれらに平行して存在するムーブメントを確認できました。 Twisted では、非同期プログラミングこそがその存在の中心的な動機です。 フレームワークとしての Twisted の実装は Python とは分離されており (Python には軽量スレッドのようなコアとなる非同期の抽象化が欠けています)、Twisted を使ってプログラムを書くときは非同期モデルが前面に押し出されるか中心に居座ります。
Erlang では, 非同期という考え方は依然としてプログラマに見えますが、その詳細は言語とランタイムシステムの組織の一部であり, 同期プロセス同士で非同期メッセージが交換されるように抽象化されます。
そして最後に Haskell では、非同期 I/O はランタイム内部のもうひとつのテクニックにすぎません。 プログラマからは広範に隠蔽され、Haskell の中心となる考え方のひとつである遅延評価を提供します。
この状況に対する何らかの深い洞察を持っているわけではありません。 多くのそして興味深い非同期モデルが現れる部分と、それを表現できるたくさんの異なる方法を指摘しているだけです。
Haskell についてここまで述べたことがあなたの興味をそそるなら、さらに学び続けるには Real World Haskell がお勧めです。 この本はプログラム言語の良い入門書がいかにあるべきかのモデルとも言えます。 あと、私は読んでいませんが、 Learn You a Haskell が良いとの話を聞いたことがあります。
Twisted 以外の非同期システムの探検と、このシリーズの最後から2番目のパートもこれでお終いです。 “パート22: おわりに”が最後です。もっと Twisted について学んでいく方法を紹介しましょう。
おすすめの練習問題¶
Twisted と Erlang と Haskell のクライアントをそれぞれ比べてください。
詩のサーバに接続するときの失敗を扱えるように Haskell クライアントを修正しましょう。 ダウンロードできる全ての詩を取得し、ダウンロードできない詩のために妥当なエラーメッセージを出力させます。
Twisted を使って作った詩のサーバの、Haskell バージョンを書いてみましょう。